JavaScript 如何运行计算密集型任务

这篇文章,我打算从 js 有哪些实现计算密集型任务的手段出发,延伸到进程和线程,再到 golang, 从而对并发有一个深刻的认知。
需求是这样的,一个 Nodejs web 后端,需要执行一个数据处理步骤,在内存中进行,非常耗时。项目用 pm2 起了四个服务,用 pm2 的观测命令可以看到,每次场景会把一个服务的 cpu 占满,运行四次就会把四个服务都占满,后面整个服务就瘫痪了,无法处理新的请求。
我们都知道,js 是基于事件循环机制来实现非堵塞 IO 效果的,且 js 是单线程运行。这意味着,JS 一个时刻只能处理一件事。如果一个任务占据了 js 线程过长时间,js 就不能处理后续的请求,表现就是服务挂掉了。因此,cpu 密集任务在 js 中是一个致命问题。
worker threads 和 child process
既然这一切是单线程的锅,那么如果有新的线程或者进程来处理这个 cpu 密集任务,把主 js 线程解放出来,这样服务就能正常处理请求了。所以,引入 js 中两个处理并发计算的工具:worker threads和child process。顾名思义,前者是新线程,后者是新进程。
这里顺便复习一下线程和进程的关系。就记住一句话,进程大于线程,进程之间互相隔离,线程之间共享内存。一个 Nodejs 进程,默认只有一个主线程,不过也有别的线程,比如 I/O 线程,还有我们即将谈到的工作线程(worker threads)。
废话少说,直接上代码。这里我们定义一个朴实无华的 cpu 密集任务,即 1e10 级别的累加任务:
// CPU 密集型任务:计算 1 到 N 的总和
function heavyComputation(n) {
let sum = 0;
for (let i = 1; i <= n; i++) {
sum += 1;
}
return sum;
}
worker threads
worker的代码如下:
// worker.js
const { parentPort, workerData } = require("worker_threads");
// CPU 密集型任务:计算 1 到 N 的总和
function heavyComputation(n) {
let sum = 0;
for (let i = 1; i <= n; i++) {
sum += 1;
}
return sum;
}
// 计算并发送结果回主线程
const result = heavyComputation(workerData);
parentPort.postMessage(result);
// -----------------
// main.js
const { Worker } = require("worker_threads");
function runWorker(workerData) {
return new Promise((resolve, reject) => {
const worker = new Worker("./worker.js", { workerData });
worker.on("message", resolve); // 接收子线程的结果
worker.on("error", reject); // 子线程发生错误
worker.on("exit", (code) => {
if (code !== 0) {
reject(new Error(`Worker stopped with exit code ${code}`));
}
});
});
}
// 调用 worker 执行 CPU 密集型任务
(async () => {
try {
console.time("1");
console.log("Main thread: Starting CPU-intensive task...");
const result = await runWorker(1e10); // 计算 1 到 100000000 的总和
console.log(`Main thread: Task result is ${result}`);
console.timeEnd("1");
} catch (error) {
console.error("Error:", error);
}
})();
console.log("other task");
执行结果:
Main thread: Starting CPU-intensive task...
other task
Main thread: Task result is 10000000000
1: 11.216s
注意上面这种写法是把 worker 包进一个 promise 里面,这样 js 就把 runWorker 作为一个异步事件处理,并放入事件队列。当 resolve 被调用时,说明 worker 执行完毕,js 就会把回调事件 resolve 从任务队列中取出执行。在上面的代码中,worker.on("message", resolve) 等同于worker.on("message", (result)=>{resolve(result)})。
回到 worker,它就是启动一个线程用于执行 cpu 密集任务,从而将主线程解放出来。
child process
// compute.js
process.on("message", (n) => {
// CPU 密集型任务:计算 1 到 N 的总和
function heavyComputation(n) {
let sum = 0;
for (let i = 1; i <= n; i++) {
sum += 1;
}
return sum;
}
const result = heavyComputation(n);
process.send(result); // 将结果发送回主进程
});
// ------------------------
// main.js
const { fork } = require("child_process");
// 创建子进程
const computeProcess = fork("./compute.js");
// 监听子进程消息
computeProcess.on("message", (result) => {
console.log(`Main process: Task result is ${result}`);
console.timeEnd("1");
computeProcess.kill(); // 任务完成后杀死子进程
});
// 发送任务数据到子进程
console.time("1");
console.log("Main process: Starting CPU-intensive task...");
computeProcess.send(1e10);
console.log("other task");
打印结果:
Main process: Starting CPU-intensive task...
other task
Main process: Task result is 10000000000
1: 11.116s
可以看出,两者执行事件大致相同。
两者比较
进程由于其相互间的隔离性较好,所以适合在执行外部程序或脚本时使用,或者需要 standard input/output 作为消息传递的场景。
线程则因其上下文切换开销小,故而是 cpu 密集任务的首选。
并行的力量
首先对并发和并行的概念做一下区分。
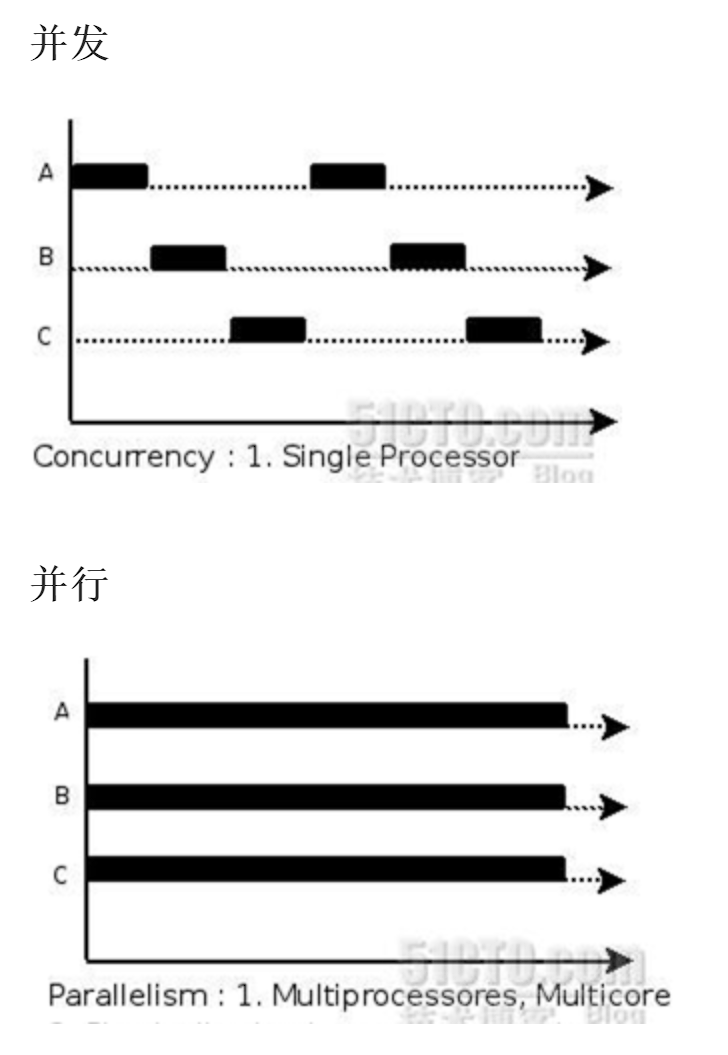
并发是cpu的一个核上进行多个任务执行,而并行则是多个核同时执行多个任务。有赖于现代cpu的核心数越来越多,并行是提高程序执行效率的手段之一。
在上面的例子中,因为程序恰好可以分割成各个互不相关的子任务,所以可以利用多核执行,从而提高效率。所以,worker_threads的代码可以进一步改造为:
const { Worker, isMainThread, parentPort, workerData } = require('worker_threads');
const os = require('os');
// 定义一个计算函数(在 Worker 中运行)
function calculateRange(start, end) {
let sum = 0;
for (let i = start; i <= end; i++) {
sum += 1;
}
return sum;
}
// Worker 逻辑
if (!isMainThread) {
const { start, end } = workerData;
const result = calculateRange(start, end);
parentPort.postMessage(result); // 将结果返回给主线程
}
// 主线程逻辑
if (isMainThread) {
const total = 1e10;
console.log('core nums:', os.cpus().length)
const threads = os.cpus().length; // 设置 Worker 数量
const range = Math.ceil(total / threads);
let completed = 0;
let finalSum = 0;
console.time('1')
for (let i = 0; i < threads; i++) {
const start = i * range + 1;
const end = i === threads - 1 ? total : (i + 1) * range;
const worker = new Worker(__filename, { workerData: { start, end } });
worker.on('message', (result) => {
finalSum += result;
completed++;
if (completed === threads) {
console.log(`Final Sum: ${finalSum}`);
console.timeEnd('1')
}
});
worker.on('error', (err) => console.error(err));
worker.on('exit', (code) => {
if (code !== 0) console.error(`Worker stopped with exit code ${code}`);
});
}
}
打印结果:
core nums: 16
Final Sum: 10000000000
1: 1.295s
在网络服务场景中,如果一个接口里面包含cpu密集任务,每次请求都要启动和销毁这么多的worker,会耗费额外资源。因此,可以借助线程池的概念进行优化,比如引入外部库
workerpool。
Nodejs vs Go
Go 是一门编译型语言,且拥有非凡的性能。把上面的累加任务用 go 的写法:
package main
import (
"fmt"
"time"
)
func main() {
s := 0
start := time.Now()
for i := 0; i < 1e10; i++ {
s += 1
}
end := time.Since(start)
fmt.Println("1", end)
}
结果只用了 6 秒钟!只有 node 的一半!那么,如果通过 child_process 来调用 go 编译的二进制文件,速度如何呢?
把上面的 child process 的 main.js 改造成:
const { spawn } = require("child_process");
// 定义计算任务参数
const target = 1e10;
// 创建子进程调用 Go 编译的二进制文件
console.time("1");
console.log("Main process: Starting CPU-intensive task...");
const computeProcess = spawn("./compute.exe", [target.toString()]); // 假设编译后的文件名为 `compute`
computeProcess.stdout.on("data", (data) => {
console.log(`Main process: Task result is ${data}`);
});
computeProcess.stderr.on("data", (err) => {
console.error(`Main process: Error occurred: ${err}`);
});
computeProcess.on("close", (code) => {
console.timeEnd("1");
console.log(`Main process: Subprocess exited with code ${code}`);
});
console.log("other task");
同时编写 go 程序:
package main
import (
"fmt"
"os"
"strconv"
)
func main() {
if len(os.Args) < 2 {
fmt.Fprintln(os.Stderr, "Error: Missing argument")
os.Exit(1)
}
// 将输入参数转换为整数
n, err := strconv.ParseInt(os.Args[1], 10, 64)
if err != nil {
fmt.Fprintln(os.Stderr, "Error: Invalid number")
os.Exit(1)
}
// 计算从 1 到 n 的总和
var sum int64
for i := int64(1); i <= n; i++ {
sum += 1
}
// 输出结果
fmt.Println(sum)
}
在终端中运行以下命令,将 compute.go 编译为二进制文件:
go build -o compute.exe compute.go
node main.js运行主程序,结果:
Main process: Starting CPU-intensive task...
other task
Main process: Task result is 10000000000
1: 3.379s
Main process: Subprocess exited with code 0
时间缩短到约 1/3。
上面提到的worker_threads可以利用并行计算的优势,而Go更是这方面的专家。借助于goroutine,Go能创建出多个并发执行。
package main
import (
"fmt"
"sync"
)
func main() {
// 定义计数范围和批次
total := 10000000000
batchCount := 100
batchSize := total / batchCount
// 创建 WaitGroup 和结果 channel
var wg sync.WaitGroup
results := make(chan int, batchCount)
// 启动 goroutine 分批计算
for i := 0; i < batchCount; i++ {
start := i*batchSize + 1
end := (i + 1) * batchSize
wg.Add(1)
go func(start, end int) {
defer wg.Done()
sum := 0
for j := start; j <= end; j++ {
sum += 1
}
results <- sum
// fmt.Printf("Batch %d-%d calculated sum: %d\n", start, end, sum)
}(start, end)
}
// 等待所有 goroutines 完成并关闭结果 channel
go func() {
wg.Wait()
close(results)
}()
// 汇总所有批次的结果
totalSum := 0
for sum := range results {
totalSum += sum
}
// fmt.Printf("Total sum from 1 to %d is: %d\n", total, totalSum)
fmt.Println(totalSum)
}
执行时间仅需 538.356ms.
总结
Nodejs 一直有一种说法,也就是擅于 IO 密集型任务,而不是 cpu 密集任务。这篇文章用详细的例子印证了这个说法,但是不仅于此,而是用worker_threads核child_process探索更多nodejs执行此类任务的 潜力。经实验表明,借助于工作线程核并行运算,速度能提升10倍。另外,与 Go 语言做了比较,发现 Go 的执行效率比 Nodejs 高了很多。
参考文章: